CASE (computer aided Software Engineering, Computer-Aided Software Engineering) is a computer technology that assists computer software development, including providing computer-aided support in the process of software development and maintenance and introducing engineering methods in the process of software development and maintenance. CASE tools are a special class of software tools used to assist in the development, testing, analysis and maintenance of another computer program and related documents. CASE tools can be divided into the following types, namely, management tools, editing tools, configuration management tools, prototype tools, method support tools, language processing tools, program analysis tools, testing tools, debugging tools, documentation tools and reengineering tools. They can be used to assist different activities in the software development process.
The above CASE tools can also be directly applied to the GIS software development process to assist the implementation of corresponding software development activities. In addition, we can also specialize CASE tools in the field of GIS to better support GIS development activities. The following describes another aspect of the application of CASE tools in GIS development: the application of configuration management tools to support spatial process and spatial data configuration management.
Software configuration management (Configuration Management) is a technology to identify, organize and control changes, which can minimize the confusion caused by changes in the software development process. At present, configuration management tools are relatively mature, and the basic functions provided include:
Configuration identification: in the process of software development, a variety of related documents are constantly changing, and the content at each moment in the process of change is called a configuration, which can be named for control and management.
Version control: version control is used to manage different versions of configuration objects established during software engineering.
Change control: change control is realized through “Check out” and “Check in” mechanisms when multiple people jointly develop software without confusion caused by jointly modifying the same file.
Configuration status reports: configuration status reports reflect the history of development activities by systematically recording the development process.
Configuration audit: the purpose of the configuration audit is to verify the technical and administrative integrity of the products throughout the software lifetime, and to ensure that the contents of all documents do not change beyond the scope of the original software requirements.
In fact, by controlling the configuration of different versions, you can manage the entire software process, track the changes of each document, and determine the dependencies between documents. These characteristics can also be applied to spatial process and spatial data management and control.
In the process of building a large-scale GIS application, we often have to deal with a large amount of data. In a nutshell, it has the following characteristics:
Large amount of data
Data change frequently, such as land use maps and cadastral maps interpreted from remote sensing images;
The derived data can be obtained from the spatial model operation of one or more pieces of data, in other words, the data are dependent on each other through the spatial model;
The spatial model is also constantly changing.
At this point, the data becomes chaotic and difficult to control, and managers are unable to understand the progress of the entire project. The concept of configuration management is introduced into GIS, which can manage multiple versions of spatial data and spatial model, and then support spatial process and assist the establishment of GIS application system.
The concept of Process is currently applied to different fields, referring to computer programs controlled by “Meta-program” and complex sequences of data exchange. The concept of process is very helpful in solving some problems related to heterogeneous platforms and application environments. Such questions include:
Interoperability, which can be solved on a process-based basis rather than limited to ordinary situations.
Distribution provides adequate support when writing distributed applications based on existing tools.
Forward recovery is guaranteed by using every step of the database persistent record process.
Monitoring is based on the current state and previous state of the process saved in the database.
History backtracking is realized based on the query and data mining of the storage process state database.
These problems are common in many different application fields, from virtual enterprises and business environments to software engineering and scientific data management, which illustrates the extensive application of process concepts.
For GIS, most of the research activities focus on the following issues: spatial data representation, indexing, storage and retrieval. It can be said that this is just the result of an attempt to extend database technology to traditional datasets. The problem of spatial process is not only related to the spatial model, but is illustrated by an example below.
Figure 16-21 is a typical combination of spatial models, forming transform sequences applied to different data sets. For example, elevation sampling data is used as input to the numerical elevation reconstruction algorithm to generate topographic maps with interpolated elevations. The topographic map is then used by the slope analysis program to extract the slope length, slope and aspect of different slopes. These results, together with soil sampling data and vegetation cover information in the region, are used as input data to attempt to predict future erosion model models in the region. Vegetation cover data are obtained by comprehensive analysis of soil sampling data, vegetation sampling data and satellite images. The vegetation cover data is also used as the input data of the vegetation succession model, which estimates the possible changes of vegetation cover in the future according to the predicted erosion data. It is a similar step-by-step process when considering the effect of precipitation. Figure 21 shows that all spatial models are organized together to form a complex set of operations that represent different geographical phenomena. Fig. 256 Figure 16-21: example of spatial process: soil and water loss model [G.Alonso] # 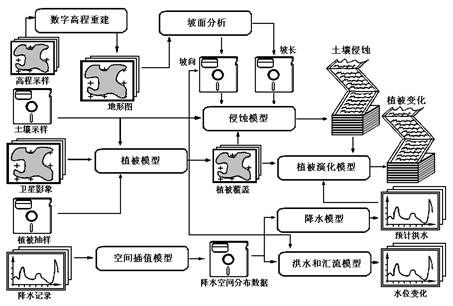
This example illustrates some requirements that, naturally, are very similar to those of process management. These necessary and simplified requirements are listed below, including model language, distribution and parallelism, and query capabilities.
Model language: in any process support system, the key component is the language that can describe the process. Given a complex geographic process model, the model language must be structured, allow nesting, and can be easily reused. Any geographic process should be easily used to construct a larger geographic process. In addition, given the complex execution environment, the language must provide support for event and exception handling mechanisms. Events can be used to notify the system and trigger the execution model to produce updated data when the dataset changes. Similarly, considering the exceptions, there must be a reliable mechanism to deal with them to prevent the system from deviating from the pre-described behavior, resulting in the exit of the entire model execution. Because in workflow systems, the language must allow external objects to be defined and registered as well as applications. In the application of geographic process, it should be more like this, because in geographic process management, both algorithms and spatial data will be external to the system, and the registration of external entities is the basis of interoperability.
Forward recovery in distribution and parallelism: to reduce the cost of executing such complex geographic processes, their different steps should be parallel whenever possible. Generally speaking, we assume that the basic platform is a group of (cluster) microcomputers or workstations and does not require the same operating system. Each step in the geographical process can be assigned to different nodes in this group, so the adoption of parallel mechanism is an inherent feature of the model. Similarly, multiprocessor machines use a similar implementation. As a direct consequence, and because of the cost of the models and the time it takes to execute them, there must be a mechanism to prevent all calculations from being lost when errors occur. This is the concept of forward recovery, which resumes execution from an interruption caused by an error. It will be useless to provide a system in which complex geographic processes can only be executed from beginning to end without interruption, and can not be dynamically modified to correct errors. In general, the purpose of constructing a geographic process is not so much to get its results as to test the legitimacy and availability of the relevant geographic models. For these reasons, the system must support single-step execution and be able to stop, check, make changes, and resume execution at any point of execution. Such a function can only be achieved through accurate monitoring of the execution of geographic processes.
Dependency query capability: in the geographic process, if you do not understand the model and input data, you will not be able to explain the data generated by that data and the model. This leads to well-known issues such as “family tracking” (Lineage tracking), “change propagation (Change propagation)” and “version”, which are no different from history tracking in a more general process. In this environment, there will be some typical query questions, such as “which model uses algorithm X?” What will happen if dataset Y changes? And “what data is used to generate data Z?” Therefore, the system must support the following functions, including automatic change propagation (re-executing the model to create a new version of the output data when the input data changes), change notification, and process control (as long as a dataset exists, the model used to create it will retain a copy. Similarly, as long as other processes use a subprocedure and keep a copy of that subprocedure), the system can be really useful. Only if there is an appropriate mechanism to track the dependencies between data, and there is an efficient way to extract information from these dependencies, the system can provide the above functions well. Process modeling is an important research direction of current software engineering. By formally describing the development process, and then achieving more “accurate” process management, it can also be applied to spatial processes. Because of the complexity of the process itself, it is difficult to establish a complete process model. Using configuration management tools, we can realize the control and management of data, model and even process to a certain extent.